
도순씨의 코딩일지
딥러닝 :: 로지스틱 회귀, 퍼셉트론, 다층 퍼셉트론 본문
로지스틱 회귀
참과 거짓 중에 하나를 내놓는 과정은 로지스틱 회귀의 원리를 거쳐 이루어진다. 이것을 통해 주어진 입력 값의 특징을 추출하는 것이다.
만약에 참을 1, 거짓을 0이라고 가정한다면 선을 잇는 것이 이상해보일 수도 있다. 다음의 사진을 보면 어떻게 표현해야 할 지 조금은 감이 잡힐 것이다.

로지스틱 회귀는 1과 0인 값을 이용하여 S자 형태의 선을 그려주는 작업이다.
이러한 S자 형태로 그래프가 그려지는 함수를 시그모이드(sigmoid function)이라고 한다. 시그모이드 함수의 방정식은 다음과 같다.

여기서도 우리가 구해야할 식은 ax+b라는 것을 알 수 있다. a는 그래프의 경사도를 결정한다. a의 값이 커지면 경사가 커지고 a의 값이 작아지면 경사가 작아진다. b는 그래프의 좌우 이동을 의미한다. 여기서 a와 b는 경사 하강법에 따라서 구하면 된다.
시그모이드 함수의 특징은 y값이 0과 1 사이라는 것이다. 실제 값이 1일 때 예측 값이 0에 가까워지면 오차가 커져야 한다. 반대로, 실제 값이 0일 때 예측 값이 1에 가까워지는 경우에도 오차는 커져야 한다. 이를 공식적으로 가능케 하는 것이 로그함수이다.
퍼셉트론
입력 값과 출력 값을 구하는 함수 y는 다음과 같이 표시할 수 있다.
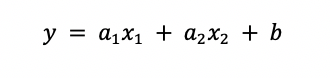
우리가 가진 값은 x1과 y1이다. 이것을 입력 값이라고 한다. 그리고 계산으로 얻는 값 y를 출력 값이라고 한다. 그러므로 출력값을 구하기 위해서는 a와 b가 필요하다. 이것이 신경망을 이루는 가장 중요한 단위인 퍼셉트론이다.
다음과 같은 식에서 기울기와 절편과 같은 용어를 조금 더 딥러닝답게 표현하면 다음과 같다.

여기서 w는 가중치이고 b는 바이어스(편향)라고 할 수 있다. 편향의 수치에 모델의 복잡도가 결정된다. 편향의 값이 높다면 모델이 단순하여 엄격한 분류 기준을 이용하여 분류한다. 반면 편향값이 낮다면 모델이 복잡하며 단순한 분류 기준을 이용하여 분류한다. 분류 기준이 단순하여 허용 범위가 넓어지기 때문이다.
다층 퍼셉트론
다층 퍼셉트론은 입력층과 출령층 사이에 숨어있는 은닉충을 만든다. 가운데 숨어있는 은닉층으로 퍼셉트론이 각각 자신의 가중치와 바이어스 값으로 보내고, 이 은닉층에서 모인 값이 한 번 더 시그모이드 함수를 이용해 최종값으로 결과를 보낸다. 은닉층에 모이는 중간 정거장을 노드(node)라고 하며 n1, n2로 표현한다.
n1과 n2의 값은 각각 단일 퍼셉트론의 값과 같다.
다층 퍼센트론으로 XOR 문제를 해결하면 다음과 같다.
@코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
import numpy as np
# 가중치와 바이어스
w11 = np.array([-2, -2])
w12 = np.array([2, 2])
w2 = np.array([1, 1])
b1 = 3
b2 = -1
b3 = -1
# 퍼셉트론
def MLP(x, w, b):
y = np.sum(w * x) + b
if y <= 0:
return 0
else: return 1
# NAND 게이트 : 모두 참일 때 거짓을 내보내는 논리회로
def NAND(x1, x2):
return MLP(np.array([x1, x2]), w11, b1)
# OR 게이트
def OR(x1, x2):
return MLP(np.array([x1, x2]), w12, b2)
# AND 게이트
def AND(x1, x2):
return MLP(np.array([x1, x2]), w2, b3)
# XOR 게이트
def XOR(x1, x2):
return AND(NAND(x1, x2), OR(x1, x2))
# x1, x2 값을 번갈아 대입해가며 최종 출력
if __name__ == '__main__':
for x in [(0, 0), (1, 0), (0, 1), (1, 1)]:
y = XOR(x[0], x[1])
print("입력 값: " + str(x) + "출력 값: " + str(y))
|
cs |
@풀이
|
1
2
3
4
|
입력 값: (0, 0)출력 값: 0
입력 값: (1, 0)출력 값: 1
입력 값: (0, 1)출력 값: 1
입력 값: (1, 1)출력 값: 0
|
cs |
* 출처
조태호, 모두의 딥러닝(2017), 길벗
'𝐂𝐎𝐌𝐏𝐔𝐓𝐄𝐑 𝐒𝐂𝐈𝐄𝐍𝐂𝐄 > 𝐃𝐄𝐄𝐏 𝐋𝐄𝐀𝐑𝐍𝐈𝐍𝐆' 카테고리의 다른 글
| 딥러닝 :: 모델 설계하기, 교차 엔트로피, 모델 실행하기 (0) | 2020.08.06 |
|---|---|
| 딥러닝 :: 오차 역전파, 활성화 함수, 고급 경사 하강법 (0) | 2020.08.06 |
| 딥러닝 :: [논문분석] 김정미 외 1인, Word2vec을 활용한 RNN기반의 문서 분류에 관한 연구 (0) | 2020.08.06 |
| 딥러닝 :: 선형회귀, 최소 제곱법, 평균 제곱근 오차 (0) | 2020.08.04 |
| 딥러닝 :: 폐암 수술 환자의 생존률 예측하기 (0) | 2020.08.04 |

